📰 KPTimes : News Article for Keyphrase Generation
The data is available at github.com. The growing number of available news article makes it hard to find relevant news articles. Journals makes newsletter to let us easily digest the the day’s news. But in order to easily search for news articles faceted navigation with keyphrases are the go-to tool. Keyphrases are word sequences that expresses key ideas of a document. We use keyphrase and keyword interchangeably in this article.

Keyphrase Extraction (KPE) is the task to assign a set of keyphrases to a document for the purpose of indexing. It can also refer to the subtask of extracting keyphrases from the document only. Keyphrase Generation (KPG) is the task of generating keyphrases for a document.
There are many dataset for evaluating KPE (cf. ake-datasets), but they don’t contain enough data to train neural models. Also, the vast majority of the datasets are made of scientific documents from the computer science domain with author-assigned keyphrases. The next Figure emphasis the fact that author keyphrases are less “coherent” and so harder for machine to model.
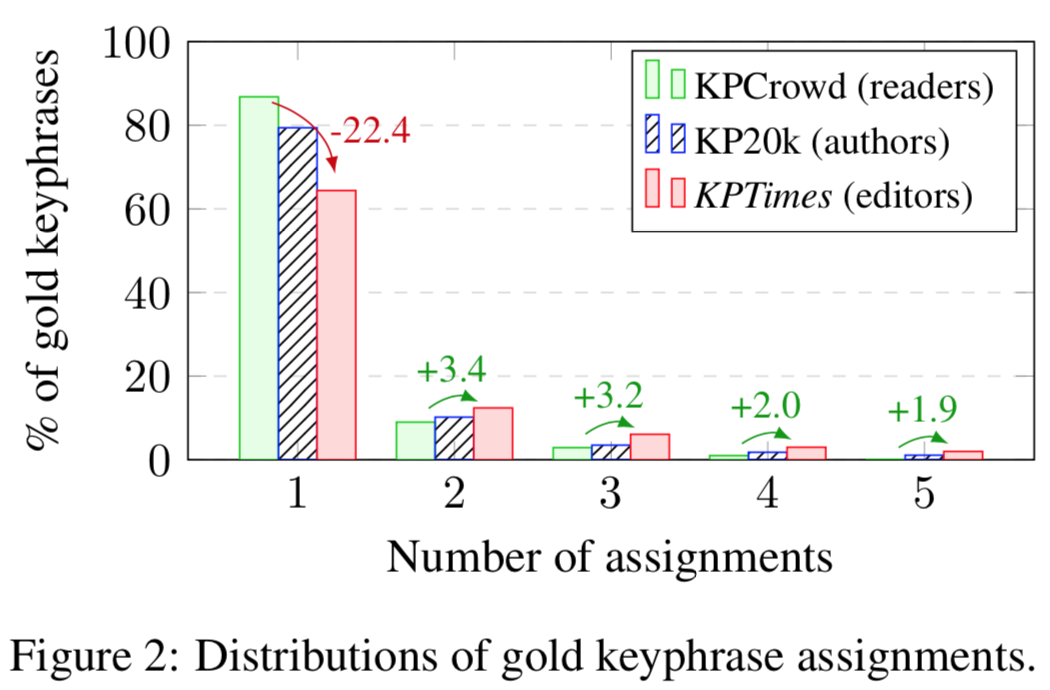
The release of KP20k – an automatically gathered scientific abstract dataset with author-assigned keyphrases – started the development of neural models for KPE. Yet, the need for a more qualitative reference and generalization ability testing are still there.
The dataset
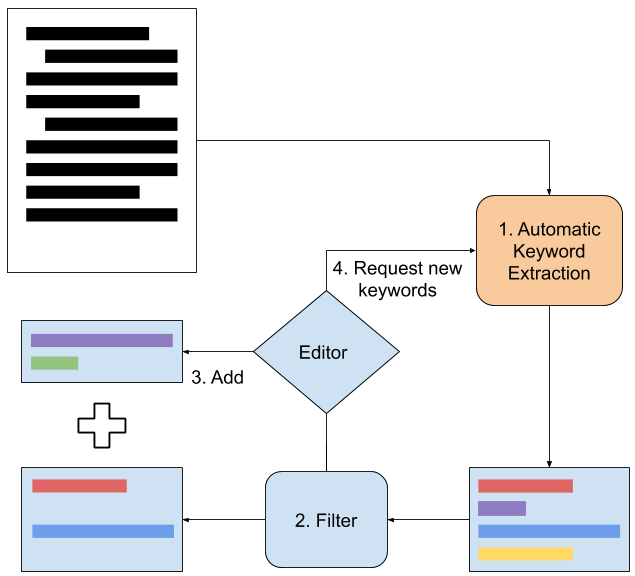
This is why we crawled the web searching for documents annotated in keyphrases. We eventually found the NewYork Times articles which metadata includes editor-curated keyphrases (see Figure below for the annotation process).
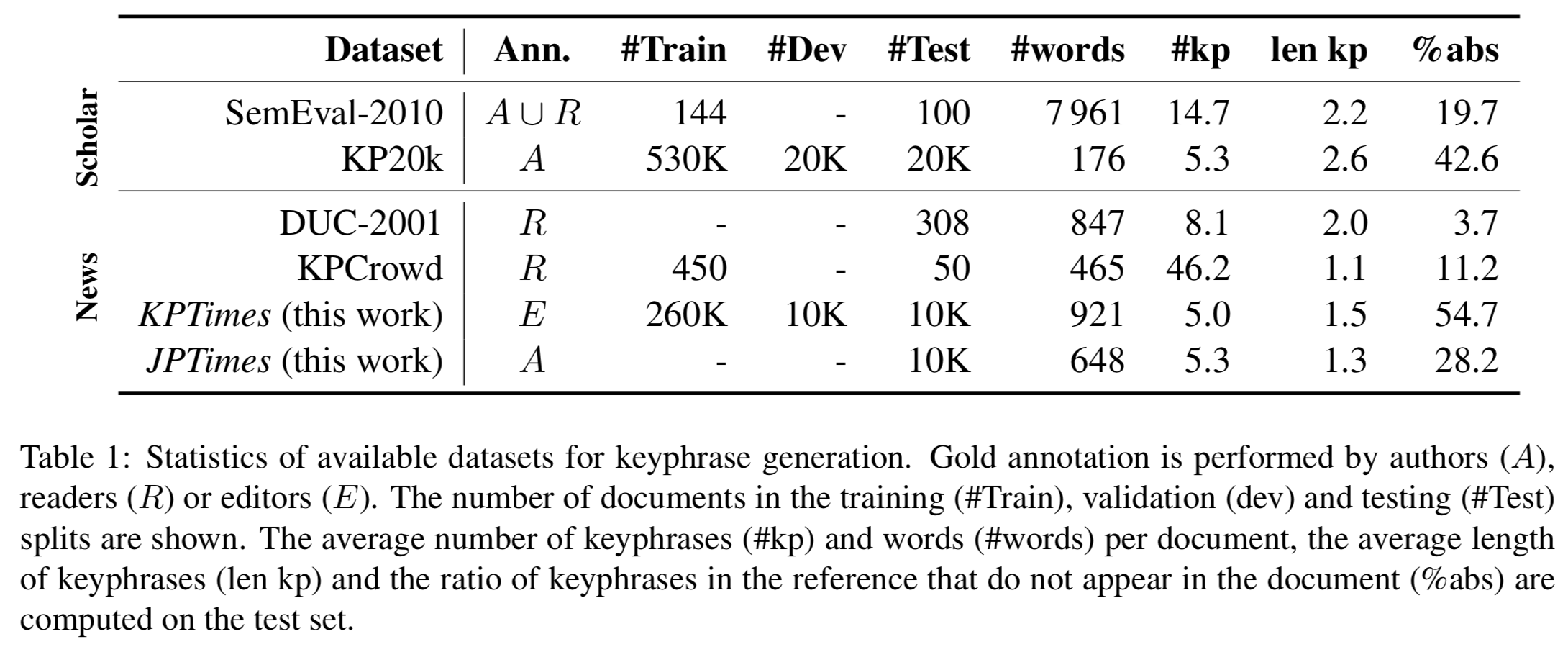
To construct the KPTimes dataset we used the free articles from 2006 to 2017 (at spiderbites.nytimes.com) as seed and used the links to other articles to crawl more documents. A total of 296,973 articles were gathered this way. We then filtered the dataset to remove to ones that were too long, too short, with too many or not enough keyphrases, recurrent articles with the same set of keyphrases. We ended up with 279,923 documents which were divided into train (259,923 doc), test (10,000 doc) and dev (10,000 doc) sets. In order to evaluate the generalization more precisely we gathered 10,000 documents from the Japan Times. The following Figure show basic statistics for KPTimes.
Proof testing the dataset
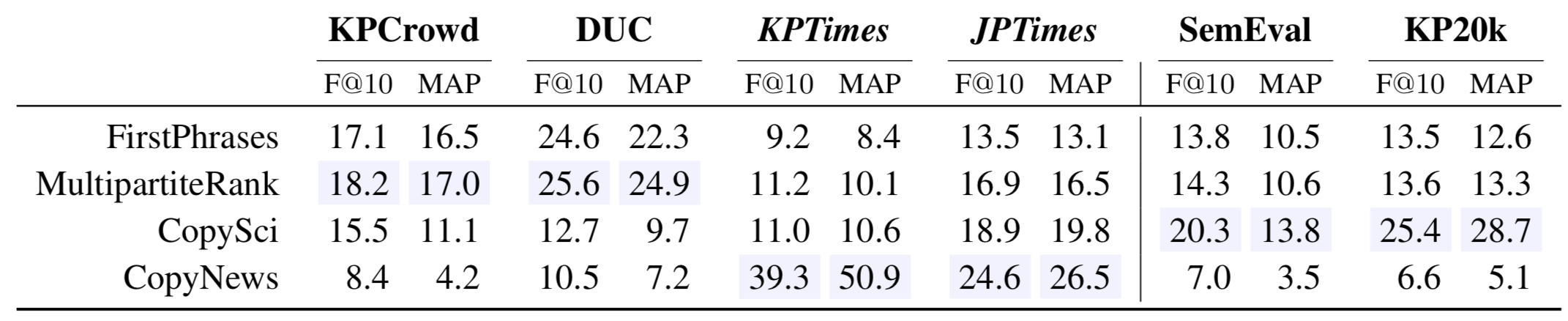
We applied the state of the art method for KPE and KPG. KPE models implementation comes from pke. CopySci and CopyNews are the same CopyRNN trained respectively on KP20k and KPTimes.
By releasing this dataset we hope to help the community in devising more robust and generalizable neural keyphrase generation models.