TP: Traitement du langage naturel
TP: Traitement du langage naturel
- Cours: Traitement du langage naturel
- Auteur: Ygor GALLINA
- Date: Janvier 2021
Préambule
Le but de ces 6 séances de TP est d’appréhender et de prendre en main les outils de traitement automatique de la langue existant pour traiter des données textuelles. Notre cas d’usage est de réaliser un classifieur de tweet anglais en fonction de s’ils ont été écrits par des républicains ou des démocrates. Nous utiliserons le jeu de données suivant : kapastor/democratvsrepublicantweets. A télécharger depuis madoc qui est séparé en 3 parties: ensemble d’entraînement, ensemble de validation et ensemble de test (sans le parti des auteurs et autrices des tweets).
Dans un premier temps nous pré-traiterons les documents, c’est-à-dire les étapes de tokenisation, racinisation, étiquetage morphosyntaxique. Ensuite nous calculerons des statistiques sur les données pour comprendre ce qu’elles contiennent. Enfin nous construirons un classifieur simple et l’évaluerons.
Exercice 1: Pré-traitements
L’objectif de cet exercice est de se familiariser avec les différents pré-traitement utilisés dans le TALN. Pour cela n’hésitez pas a consulter la documentation de chacune des librairies pour comprendre comment elles fonctionnent et à quoi correspondent les arguments de leurs fonctions.
- Téléchargez les données si ce n’est pas déjà fait et ouvrez un notebook à l’aide de la commande
jupyter notebook. - Chargez les données de validation à l’aide de la bibliothèque csv dans un dictionnaire.
- Ecrivez une fonction qui prend en entrée un document et retourne sa version tokénisée. Pour cela, utilisez la bibliothèque nltk et la fonction
nltk.word_tokenize.- Comparez le résultat de la fonction
nltk.word_tokenizeet d’une méthode de segmentation plus simplema_chaine.split(' ')sur quelques documents. - Question Quelles sont les principales différences que vous observez ?
- Comparez le résultat de la fonction
- Ecrivez ensuite une fonction qui prend en entrée un document tokénisé et ajoute pour chaque mot son étiquette morpho-syntaxique (ou POS tag) ainsi que sa version racinisée (ou stem).
- Un document sera de la forme
[('TOKEN', 'POSTAG', 'STEM'), ('TOKEN', 'POSTAG', 'STEM'), ...] - Pour les étiquettes morpho-syntaxiques vous pourrez utiliser la fonction
nltk.pos_tag(les étiquettes résultant de cette fonction proviennent de l’universal dependencies et sont explicités sur cette page, ce jeu d’étiquette est commun à l’ensemble des langues ! Cette page liste pour chaque langue ses spécificités.) - Pour la racinisation, l’algorithme de Porter, avec l’objet
nltk.stem.PorterStemmer() - Etudiez quelques documents pour vérifier la qualité des étiquettes morphosyntaxiques, et la forme racinisée des mots.
- Un document sera de la forme
- Grâce à ces fonctions pré-traitez tous les documents
- Ecrivez un code qui permet de retrouver le plus de document sur le changement climatique (climate change).
- Question Quelle est (en quelques mots) votre approche pour effectuer cela ?
- Question Utiliser les formes racinisés est-il est plus pertinent que les mots ?
- Question Les documents retournés contenant “climate” parlent-ils tous de changement climatique ? S’il y en a/avais, que pourriez-vous faire (en quelques mots) pour ne pas les retourner ?
Sauvegarde sur le disque
Le choix du format de stockage de document pré-traité n’est pas trivial, nous proposons ici d’utilise le format jsonl qui permet de sauvegarder les données au format json. Cette n’est ni la meilleure ni la seules, tout dépend de l’utilisation qui sera faite des données, de la taille des fichiers, etc.
Assurez vous que vous pouvez charger vos données après les avoir sauvegardé !
# Sauvegarder les données
with open('path/to/file.jsonl', 'w') as f:
for doc in documents:
# Chaque ligne devient un dictionnaire python
r = {
'id': doc['id'], 'Party': doc['Party'],
'Handle': doc['Handle'],
'Tweet': doc['Tweet'], # le tweet original non prétraité
'PreTweet': doc['PreTweet'] # la version prétraitée du tweet
}
# Chaque dictionnaire est serialisé en json
f.write(json.dumps(r) + '\n')
# Charger les données
with open('path/to/file.jsonl') as f:
data = [json.loads(line) for line in f]
Exercice 2: Exploration des données
En utilisant les fichiers précédemment pré-traités, extrayez et visualisez à l’aide de graphiques ou forme textuelle les informations suivantes (visualisez ces informations aussi en fonction du parti de l’auteur ou l’autrice du tweet):
- la longueur des tweets en termes de caractères et de mots pour l’ensemble du corpus, les républicains, les démocrates
- y a-t-il une différence notable entre les républicains et les démocrates ?
- la fréquence des mots et formes racinées pour l’ensemble du corpus, les républicains, les démocrates
- Faire un graphique représentant la fréquence des mots par ordre décroissant (avec une échelle logarithmique).
- Vous devez observer la loi de Zipf, seuls quelques mots constituent une grande partie du corpus.
- Ces mots n’apportent généralement que peu d’information, on dit que ce sont des mots vides (stopwords), contrairement aux mots plein (en général noms, adjectifs, verbes, …). Il est courant de les filtrer pour ne pas surcharger les modèles. Des listes de stopwords sont disponibles dans
nltk.corpus.stopwords.words, chaque bibliothèque de TAL possède en général sa liste. - /!\ Il est important d’utiliser une liste compatible avec le tokeniseur utilisé. En effet, il est fréquent que le tokeniseur segmente
"puisqu'elle"en["puisqu'", 'elle']mais que la liste de mots vide contiennepuisqu'ellemais paspuisqu'!
- les 20 n-grammes (de 1 à 5) les plus fréquent (la bibliothèque
nltkpermet cela) pour l’ensemble du corpus, les républicains, les démocrates - les 20 noms, verbes, adverbes et adjectifs les plus fréquents pour l’ensemble du corpus, les républicains, les démocrates
- le Tf-Idf sur les unigrammes en considérant chaque tweet comme un document (utilisez la bibliothèque scikit-learn)
- Nos tweets sont déjà segmentés, pour pouvoir passer en entrée des document pré-segmentés passer le paramètre
analyzer=lambda x: xaux vectorizer. L’analyzer, segmente, met en minuscule, filtre les mots vide et supprime les accents (voir les paramètres de TfidfVectorizer).
- Nos tweets sont déjà segmentés, pour pouvoir passer en entrée des document pré-segmentés passer le paramètre
# Exemple de calcul de la matrice de TfxIdf avec un petit exemple
count_vect = TfidfVectorizer(stop_words=[])
res = count_vect.fit_transform(
['Le chat est noir. Le chat mange la souris.',
'La souris mange le fromage.',
'La souris est grise. La souris court.']
)
# Visualisation de la matrice de Tf-Idf pour un petit exemple
# Visualiser la matrice de Tf-Idf d'un corpus entier n'a que très peu d'intérêt !
# Elle sera emplie de 0 ! et mettra (très) longtemps à s'afficher.
a = pd.DataFrame(res.todense())
a.rename(columns={v: k for k, v in count_vect.vocabulary_.items()}).round(2)
Paquets/commandes utiles:
collections.Counter: un dictionnaire qui compte les occurence d’un élement- Mesurer le temps d’execution d’une commande dans un jupyter notebook ``` %%time # pour une cellule entière code python
%time code python # pour une ligne
- Pour faire des graphiques
- [matplotlib](https://matplotlib.org)
- [pandas](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html) offre des moyens assez simple de faire des graphiques.
- [seaborn](https://seaborn.pydata.org) fait de beaux graphiques.
```python
# exemple minimal du graphique de la fonction x^2
import matplotlib.pyplot as plt
plt.plot(range(-10, 10), [i**2 for i in range(-10, 10)])
plt.show()
Optionnel: Pistes pour aller plus loin dans l’analyse:
- Utilisez la fonction
sklearn.metrics.pairwise.cosine_similaritypour trouver les 2 tweets dont les vecteur de Tf-Idf sont les plus proches.ndarray.argmaxdonne l’indice de l’élément de plus grandnp.unravel_index(indice, shape)converti un indice en tuple d’indice
- Utiliser le Tf-Idf pour trouver l’auteur Républicain et Démocrate qui utilisent le vocabulaire le plus similaire.
- (Utiliser l’ensemble des tweets d’un auteur/d’une autrice comme document, puis utilisez la fonction cosine pour calculer la distance entre leur vecteur de TfIdf)
- Comment expliquer cette similarité ?
- Pareillement pour les 2 auteur les moins similaire dans le même parti.
- Comment identifier les thèmes principaux abordés par chaque auteur/autrice ? ou parti (santé, sécurité, …)
- Y a-t-il des différence importante de vocabulaire entre les 2 partis ?
Exercice 3 : Faire un classifieur
Premier classifieur
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
# Chargez les données de validation et d'entraînement que vous avez pré-traité
# dans un DataFrame pandas
valid = pd.DataFrame(data_valid)
train = pd.DataFrame(data_train)
def compute_columns(df):
# On extrait les lemmes
df['stem'] = df['PreTweet'].apply(lambda x: [t[2] for t in x])
if 'Party' in df.columns:
# La valeur à prédire par le classifieur sera True ou False
df['is_democrat'] = df['Party'].apply(lambda x: 'Democrat' == x)
return df
valid = compute_columns(valid)
train = compute_columns(train)
pipeline = Pipeline([
# Compute TfIdf
('tfidf', TfidfVectorizer(analyzer=lambda x: x)),
# Classify using TfIdf
('clf', LogisticRegression()),
], verbose=True)
# Entraînement du modèle
pipeline.fit(train['stem'], train['is_democrat'])
# Prédit les étiquettes
pipeline.predict(train['stem'])
# Retourne la probabilité de l'étiquette True et False.
pipeline.predict_proba(train['stem'])
# Calcul de l'accuracy du modèle sur les données d'entraînement
# Nombre d'exemple dont la prédiction est bonne / Nombre total d'exemple
pipeline.score(train['stem'], train['is_democrat'])
# Calcul de l'accuracy du modèle sur les données de validation
pipeline.score(valid['stem'], valid['is_democrat'])
Questions
- Vérifier que le code ci-dessus s’execute bien
- Entrainer le modèle avec tout le corpus d’entraînement
- Evaluer les performances d’apprentissage (avec le corpus d’entraînement) et les performances de généralisation (avec le corpus de validation). Qu’est-ce que vous remarquez ? Est-ce normal ?
- Etant donnée les prediction et la référence ci-dessous. Remplissez une matrice de confusion (exemple). La matrice de confusion nous donne une information plus précise sur les erreurs de prédiction.
- Pour info: En TALN les mesures de precision, rappel et f-mesure sont les plus courantes (on ne les utilise pas dans ce TP)
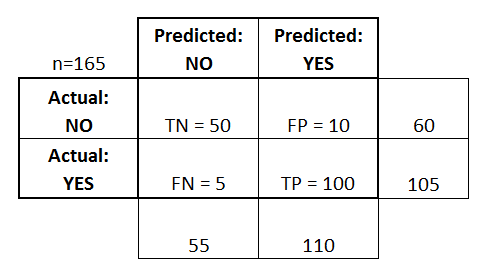{kind=link}
| Pred | Ref |
|---|---|
| True | True |
| True | False |
| False | True |
| True | False |
| False | False |
| True | False |
- Quel est le mot le plus important pour définir si un tweet a été écrit pas un démocrate ? (utilisez le vocabulaire du tfidf et les coefficients du modèle)
pipeline['tfidf'].vocabulary_représente le vocabulaire du TfIdf (le nombre correspond à l’indice du descripteur dans la classifieur).pipeline['clf'].coef_représente l’importance des descripteurs pour prédireTrue.- la fonction
predictetscoreutilisent la plus grande probabilité pour définir l’étiquette. - Fonctions utile de la bibliothèque numpy
- argmax: retourne l’indice de l’élément le plus grand
- argsort: trie les indices des elements en fonction de leur valeur
- Quelle est la fréquence de ce mot dans les tweet des démocrates ? Des républicains ?
- Y a-t-il des tweet qui ont été mal classifié mais dont le classifieur est sûr de sa prédiction ? (probabilité élevée > 0.7)
Rendu (Distantiel)
Vous devez rendre un notebook par groupe de 1 ou 2 où vous répondez aux questions des 3 exercices du TP (les questions optionelles sont optionnelles ce ne sont pas des bonus). En utilisant le classifieur de l’exercice 3:
- identifiez un exemple bien classifié et au moins un exemple mal classifié.
- Formulez une hypothèse qui explique pourquoi ces tweets ne sont pas bien classifié (inspirez vous des questions 4, 5, 6).
Faites en sorte que le notebook soit lisible. Utilisez les cellules en markdown pour entrer du texte au besoin.
Vous serez noté sur la clareté de votre notebook, la réponse aux questions et la justification de votre hypothèse.
Pour info Ajouter des descripteurs source
import json
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, Binarizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# Création des descripteurs
valid = pd.read_csv('data/ExtractedTweets_valid.spacy.csv')
valid['PreTweet'] = valid['PreTweet'].apply(json.loads)
valid['is_democrat'] = valid['Party'].apply(lambda x: 'Democrat' == x)
valid['lemmas'] = valid['PreTweet'].apply(lambda x: [t[1] for t in x])
valid['nb_lemma'] = valid['lemmas'].apply(len)
valid['has_noun'] = valid['PreTweet'].apply(lambda x: any(t[3] == 'NOUN' for t in x))
# Prétraitement des descripteurs
feature_extraction = ColumnTransformer(
[('tfidf', TfidfVectorizer(analyzer=lambda x: x), 'lemmas'),
# Les crochets autour de 'nb_lemma' sont nécéssaire
('nb_lemma', StandardScaler(), ['nb_lemma']),
# On normalise ce champs pour que les valeurs soient entre 0 et 1 (pour le corpus de test en tout cas)
('has_noun', Binarizer(),['has_noun']),
# Les valeur booleennes seront transformée en O ou 1
],
remainder='drop')
# Les colonnes non mentionnées sont ignorées
pipeline = Pipeline([
('union', feature_extraction),
('clf', LogisticRegression()),
], verbose=True)
pipeline.fit(valid, valid['is_democrat'])